How smart is IBM's Watson?
I recently completed a week-long project to analyze the performance of today’s dominant search engines when presented with questions from the famous Jeopardy! game show. The originator of the idea, Stephen Wolfram, used the results in a blog post about the similarities and differences between Wolfram|Alphawww.wolframalpha.com (where I work), and IBM’s intriguing new question-answering system.
If you have already seen one of IBM’s television spots, you’ll know that in mid-February the system (dubbed “Watson”) will compete on a special episode of Jeopardy against the two top Jeopardy champions Ken Jennings and Brad Rutter.
This event is likely to go down as an iconic example of the advance of AI technology into a realm previously reserved for human judgement, a touchstone that is similar in many ways to IBM’s successful challenge to the reigning chess world champion with its Deep BlueWikipedia computer in the late 90s.
For my part, I looked at how well traditional search engines allow one to narrow down the vast corpus of online information to just a page of potential answers to a Jeopardy clue. Not badly, it turns out, although Watson will surely advance the state of the art in text-corpus question answering.
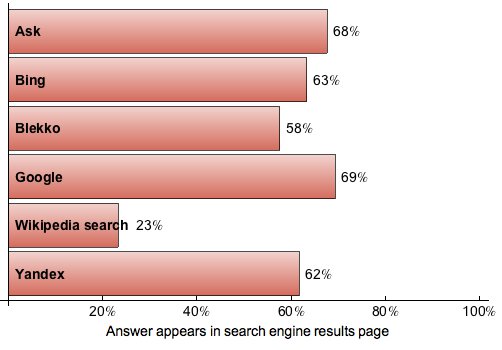
You can find more information on Stephen’s blog postbit.ly, but I’ll reproduce the main bar chart here, along with a fun little word-cloud I made of the types of entities that occur as the answers to roughly 200k Jeopardy clues. For one thing, it’s interesting how close all the major engines are now becoming, as powerful web search increasingly becomes a commodity we take for granted.